Speculative decoding and diffusion
Speculative decoding and diffusion can emit multiple tokens from one engine step. A step can deliver one verified token plus accepted drafts, or a diffusion block. Capture and replay preserve this chunk structure.
On the capture side the tap records, per output chunk, one itl_ms gap and the number
of tokens that chunk delivered in a parallel itl_tokens array (omitted for plain
autoregressive captures, so old traces are unchanged). The first chunk has no gap; its
size is output_tokens - sum(itl_tokens). With --step-stats-out the tap also writes
a per-step SchedulerStats sidecar, which under speculative decoding carries
spec_decoding_stats (per-position acceptance) from the vLLM engine.
There are two replay modes for this structure:
- Modeled (
--latency-trace): the latency model draws the recorded(gap, tokens)pairs jointly from donor pools fitted to the capture. A step the capture saw deliver four tokens replays as one four-token message after a sampled gap, never four messages at gap/4. It reproduces the burst distribution, not an individual request's recorded sequence, so sampling drift is expected. - Replay (
--replay-steps): each matched request emits its recorded chunk sizes at its recorded gaps (the timing analogue of--replay-tokens; requests resolve to records via--replay-match). This mode replays recorded timing but does not transfer to a different workload.
Either way the simulator re-derives spec_decoding_stats from the bursts it emits:
speculative budget K = max(itl_tokens) - 1, with a burst of N tokens reported as 1
target token plus N-1 accepted drafts. Scheduler stats therefore use the same
structure as the capture. Autoregressive traces report no spec stats, matching a vLLM
engine with speculation off.
# 1. Capture: vLLM engine with ngram spec decode behind the tap (writes
# tap-trace.jsonl + step-stats.jsonl). See deploy/trace-capture/ for manifests.
just capture-up && bash deploy/trace-capture/run-capture.sh && just capture-down
# 2. Replay the recorded schedule with verbatim per-request bursts and gaps.
cargo run --release --bin vllm-vcr -- inspect calibrate-e2e \
/tmp/trace-capture-h200/tap-trace.jsonl --replay-arrivals \
--sim-arg=--replay-steps=/tmp/trace-capture-h200/tap-trace.jsonl \
--dump-trace /tmp/spec-replay.jsonl
# 3. Plot capture vs replay: burst sizes, per-chunk pacing, acceptance.
uv run scripts/plot_calibration.py \
--spec-fidelity real=/tmp/trace-capture-h200/tap-trace.jsonl \
--spec-fidelity replay=/tmp/spec-replay.jsonl \
--spec-steps real=/tmp/trace-capture-h200/step-stats.jsonl \
--out-dir docs/images
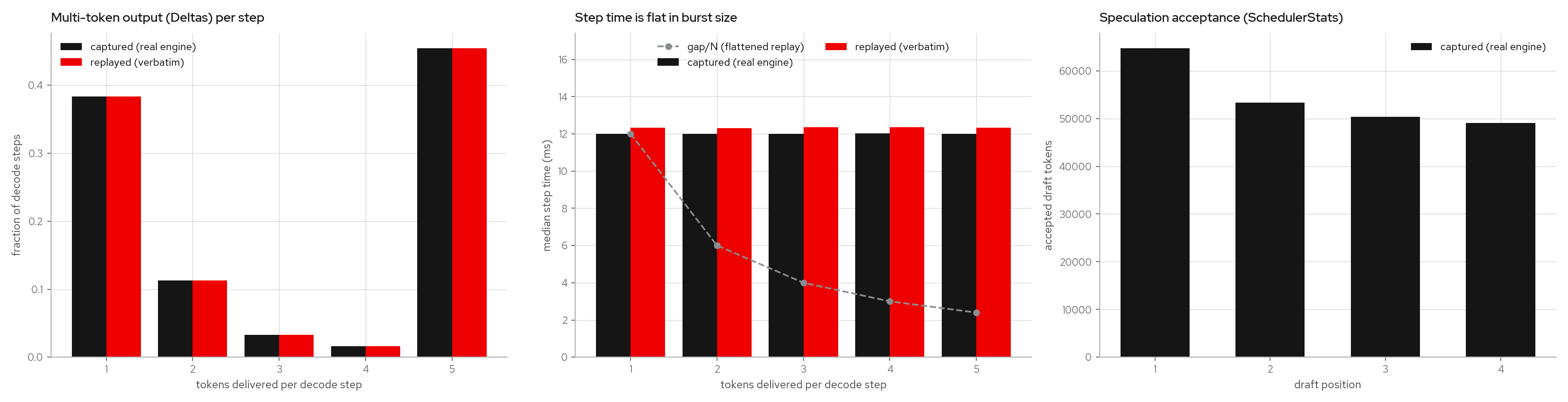
The figure is the verbatim --replay-steps path (a 4096-record Qwen3-8B run; ngram on
this workload accepts often, so ~45% of steps deliver the full 5 tokens). Left: tokens
delivered per decode step, captured vs replayed. Middle: step time vs burst size;
speculation verifies all K drafts in one target forward pass, so median step time is
~flat in the burst size (~12ms whether the step delivered 1 or 5 tokens). The dashed
line is the ~gap/N result that would appear if one chunk were split into N equal gaps.
Right: per-position draft acceptance read back from the SchedulerStats sidecar (pass
a second --spec-steps replay=... to overlay the simulator's own emitted stats).
Covered without a GPU by tests/spec_replay_fidelity.rs and replay_steps/engine unit
tests.