Calibration with engine captures
The recording tap (vllm-vcr record, deployment manifests in
deploy/trace-capture/) sits between the
vLLM Rust frontend and a headless vLLM engine (Qwen3-8B, TP=1, H200), recording
per-token inter-token gaps server-side over in-pod localhost ZMQ.
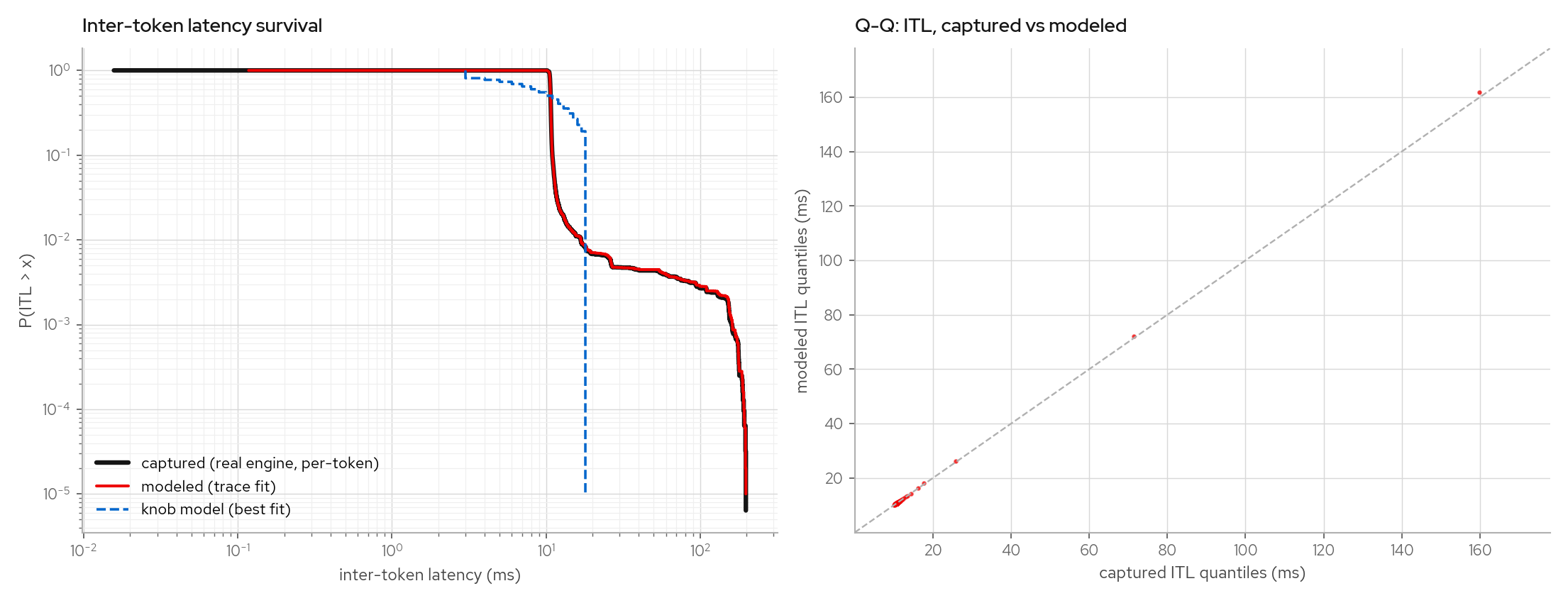
This page explains the figures used to validate the trace-fitted latency model. The important point: the model is not replaying a single request's gaps. It samples from captured observations conditioned on request shape and concurrency, so it can be tested out of sample.
The figures below plot captured vs TraceLatency vs best-fit KnobLatency per-token
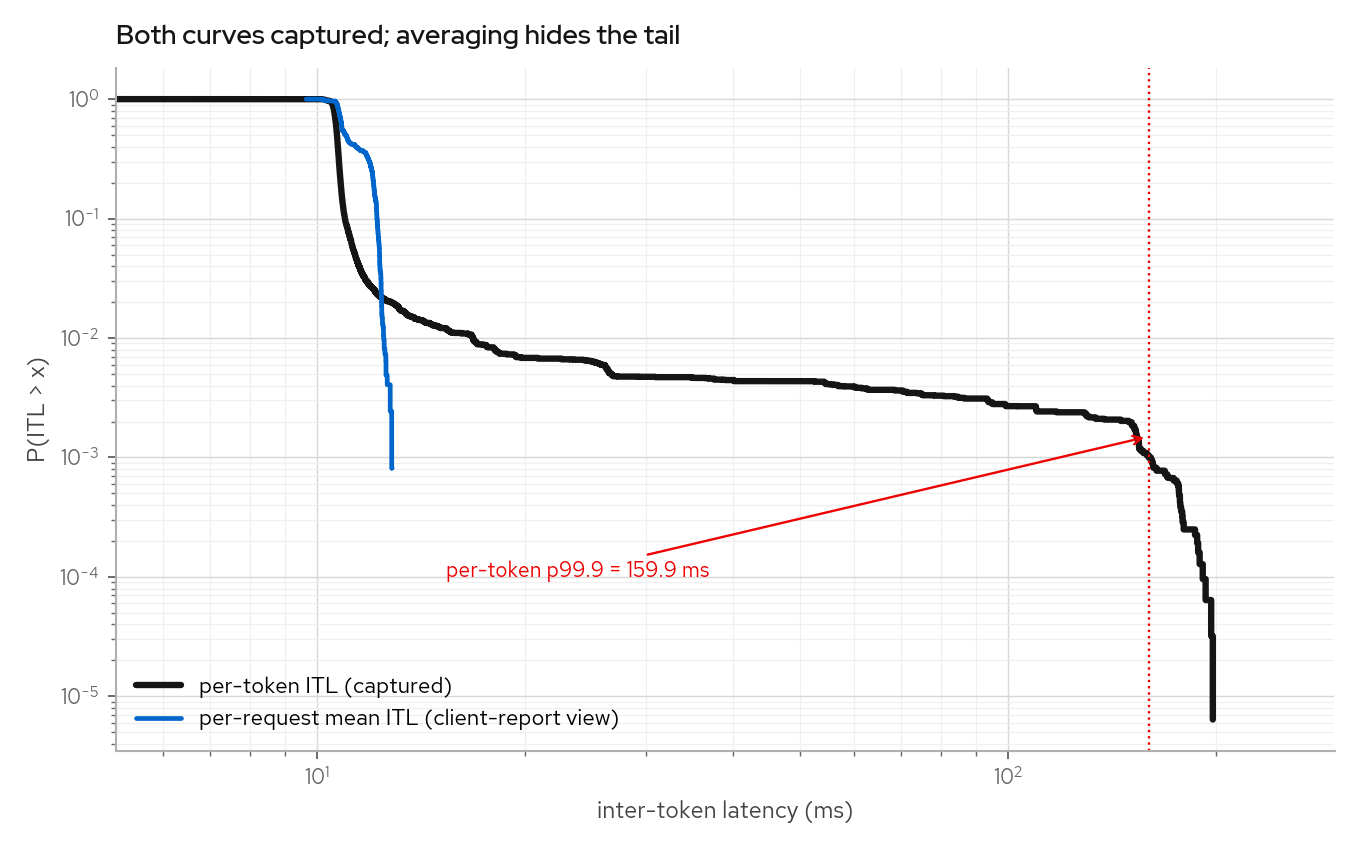
ITL (survival curve and Q-Q plot), and the same trace as pooled per-token ITLs vs
per-request mean ITLs. Client-side benchmark reports such as guidellm usually expose
per-request means because they record first/last token timestamps. The knob model's
[0.3*mean, 1.7*mean] clamp appears as a vertical cutoff before the captured tail.
To regenerate from any trace with per-token itl_ms arrays:
cargo run --bin vllm-vcr -- inspect calibrate trace.jsonl --dump-samples samples.json
uv run scripts/plot_calibration.py --samples samples.json --trace trace.jsonl --out-dir docs/images
Comparison with llm-d-inference-sim
Same workload (deploy/trace-capture/loadgen.py, concurrency 1 and 16, 512/128
tokens) against three targets: the H200 engine (tap-recorded), this simulator with its
latency model fit from the canonical fitting set (a different workload, the
counterfactual setting), and the Go
llm-d-inference-sim (v0.9.1) with its
latency knobs fit to the same trace (the in-sample setting). Both simulators ran on the
same host and were measured client-side by the same load generator. The engine curves
are the tap recording. Both simulators' timing is modeled.
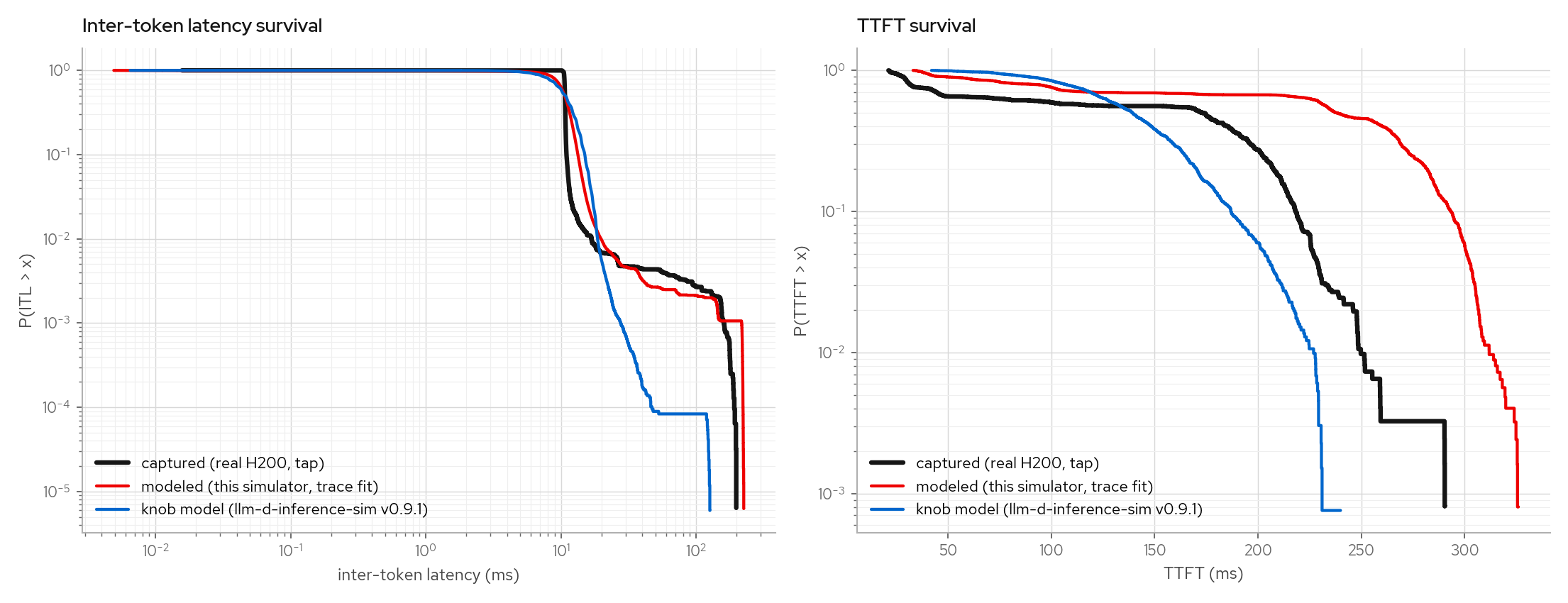
The step model over-predicts TTFT for this saturated fixed-concurrency workload by about 70ms at the median, a known calibration gap in the out-of-sample fit. The knob model clamps both tails by construction.
Note: the trace's std-devs (TTFT 80ms, ITL 8ms) exceed llm-d-inference-sim's config validation, which caps std-dev at 30% of the mean, so it runs with the largest spread it accepts (39ms / 3.3ms).
# llm-d-inference-sim invocation used above
llm-d-inference-sim --port 8001 --model Qwen/Qwen3-8B --mode random \
--force-dummy-tokenizer --max-model-len 16384 --max-num-seqs 128 \
--time-to-first-token 132ms --time-to-first-token-std-dev 39ms \
--inter-token-latency 11ms --inter-token-latency-std-dev 3300us
# this simulator: vllm-rs frontend + trace-fitted model, vLLM-default scheduler
# limits; the fit is the canonical set (sweep + warm multiturn + cold multiturn)
cat traces/h200-qwen3-8b/h200-sweep-full.jsonl \
<(grep -v '"meta"' traces/h200-qwen3-8b/h200-multiturn-mtfit2.jsonl) \
<(grep -v '"meta"' traces/h200-qwen3-8b/h200-multiturn-nocache4.jsonl) > /tmp/fit.jsonl
vllm-vcr play --handshake-address tcp://127.0.0.1:5571 \
--latency-trace /tmp/fit.jsonl \
--max-num-seqs 1024 --max-num-batched-tokens 8192
Step-granular interference
The engine paces emission with a step clock that mirrors vLLM's per-step schedule: decodes claim the shared token budget first, prefills chunk into whatever remains (in admission order), and every co-running decode's gap is the composed step's duration. Chunk compute is fitted from the trace as a depth-dependent function (attention makes deep chunks cost more per token) plus a max-shape premium for budget-saturated steps; small chunks hide under the batch's decode compute. Queueing, chunk serialization, and decode elongation are produced by the step composer rather than by interference knobs.
The gate is counterfactual: fit on one workload (a constant-load sweep plus a warm multiturn capture), then predict a cold-cache multiturn (~11k-token prompts, prefix caching disabled) the model never saw, whose prefill chunks continuously interfere with running decodes. The capture shows a two-shelf ITL band; the replay reproduces the band's shape, mass (13.9% vs 14.1%), and tail.
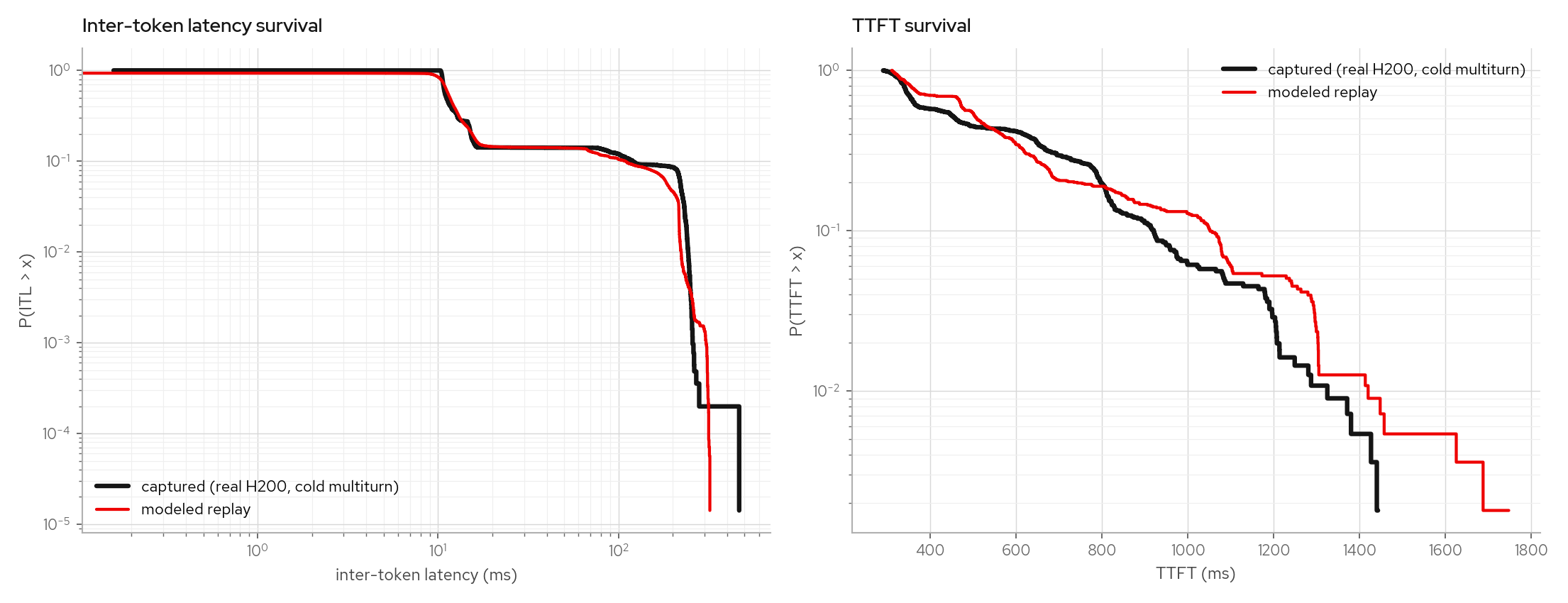
The warm-multiturn factual leg (99%+ prefix-cache hits) and a low-rate cold leg stay calibrated under the same model:
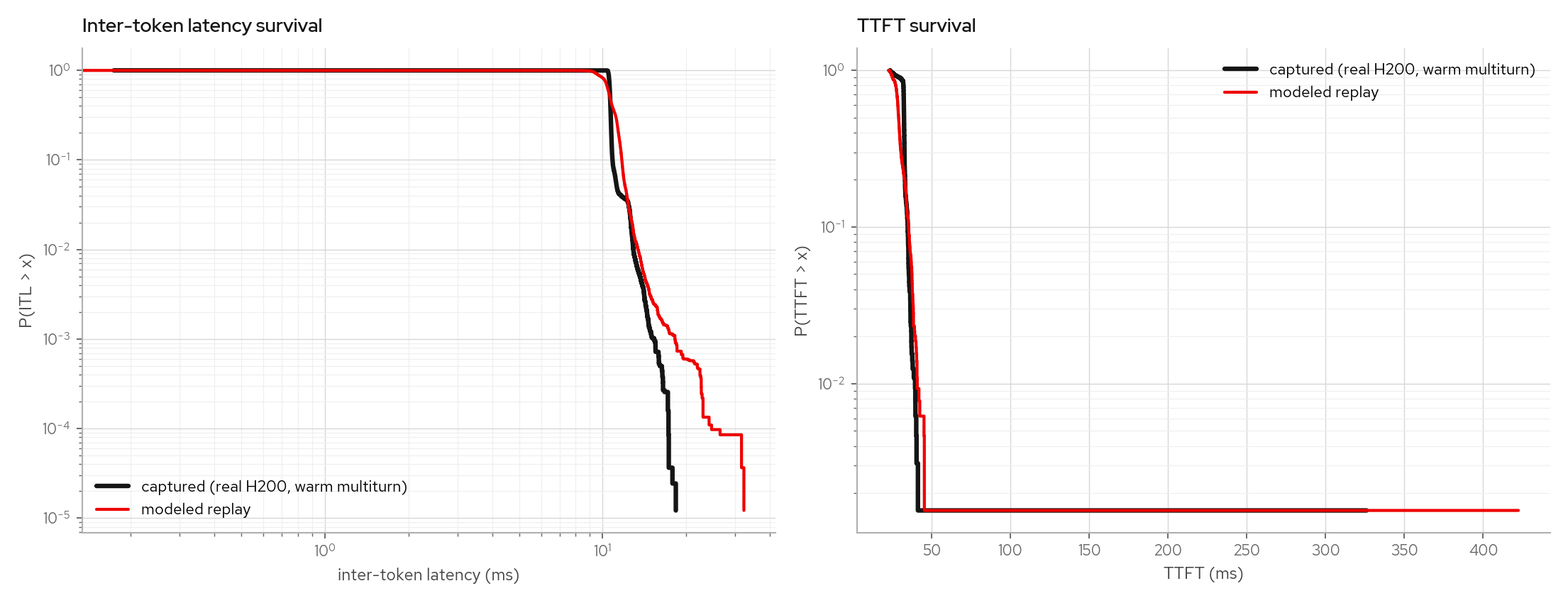
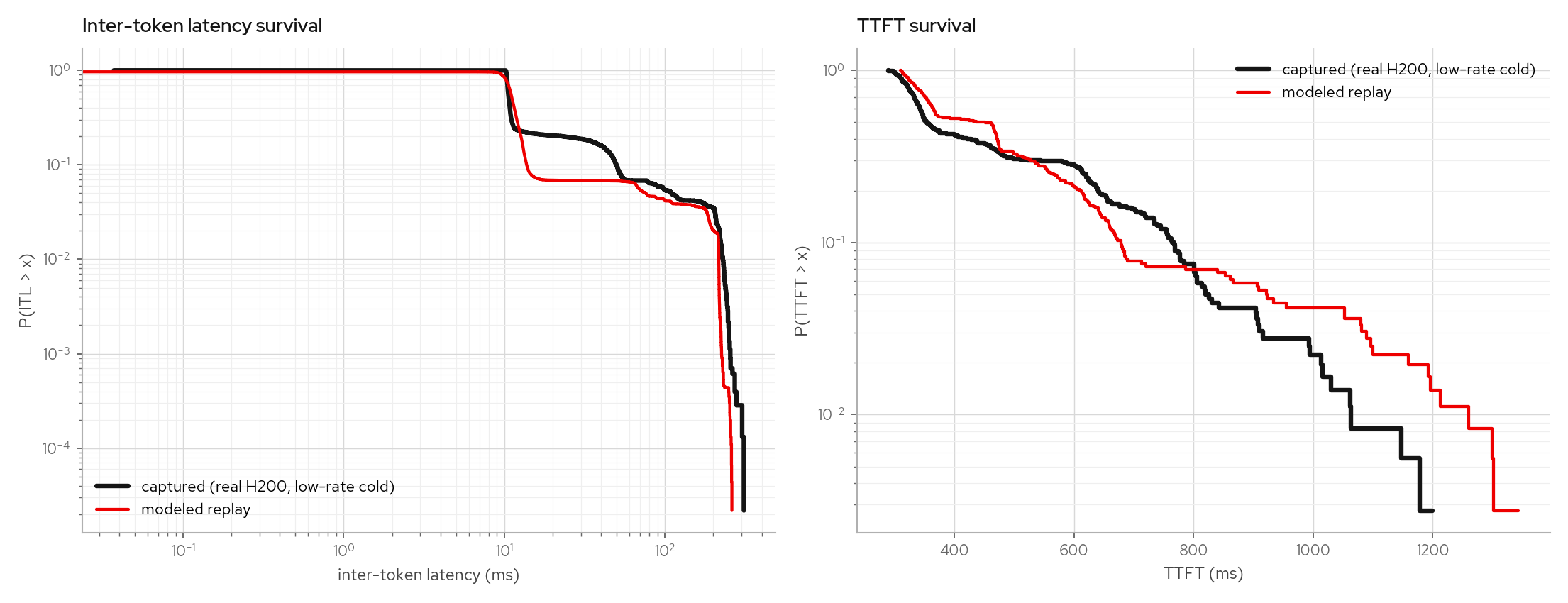
The same fit procedure refits from a Qwen3-30B-A3B MoE sweep without constant changes and reproduces its counterfactual band.