Open-loop arrival replay
The calibrations above sample the latency model closed-loop. That validates
distributions, but it does not cover TTFT queueing, prefill stalls, or concurrency
mixing from an external arrival process.
calibrate-e2e --replay-arrivals direct-replays a captured arrival schedule in real
time (each request sent at its recorded offset, open loop) and compares client-side
TTFT/ITL/request-total quantiles against the capture. The arrivals are verbatim; every
latency is still modeled. --latency-trace fits the sim's model from a different
trace, so the gate runs on an arrival process outside the fitting set.
Setup: use the same frontend → tap → engine stack as the capture rig, then run the
replay locally with vllm-vcr play as the engine. The latency model is fit from the
canonical H200 fitting set, while deploy/trace-capture/loadgen.py --pattern poisson|burst drives arrival processes the fitting set never contained.
| scenario | requests | concurrency seen | TTFT max err | ITL max err | req-total err |
|---|---|---|---|---|---|
| poisson, 4 req/s | 464 | 1-15, median 6 | 36.1%* | 1.1% | 0.2% |
| burst, 24 per 10s | 288 | 0 -> 24 spikes | 0.4% | 0.05% | 0.5% |
| multiturn agentic (see below) | 495 | 1-13 | 26.0%* | 0.9% | 2.5% |
The max-err columns are the worst single quantile across all concurrency buckets. The starred cells are small-n tail artifacts: poisson's worst cell is its n=2 concurrency-1 bucket, multiturn's is a warm-TTFT p99 where captured 103ms vs modeled 76ms differ by transport jitter the in-process replay does not model. Medians and p90s agree within ~1-2%, and request totals stay within 2.5%.
The burst scenario sends 24 simultaneous 512-token prefills to an idle engine, so TTFT is queueing-dominated (burst TTFT p50 1.2s / p99 2.0s vs poisson's 58ms / 150ms on the same config).
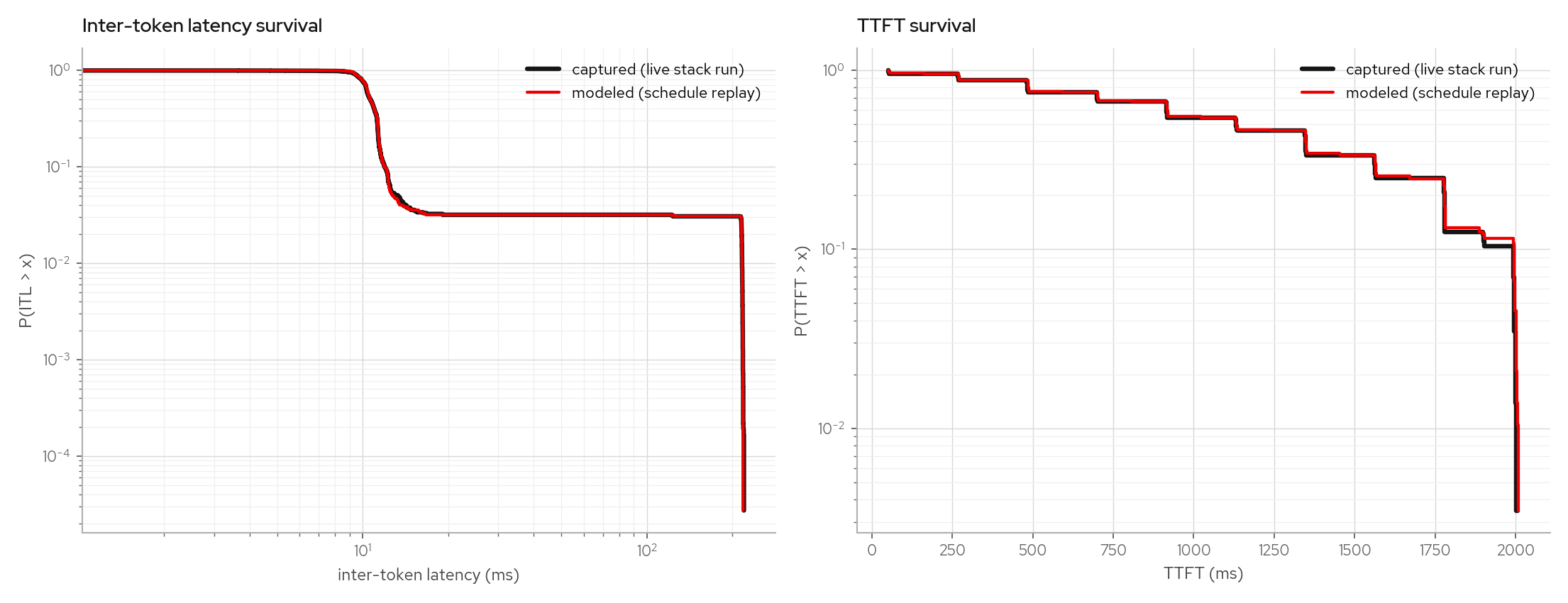
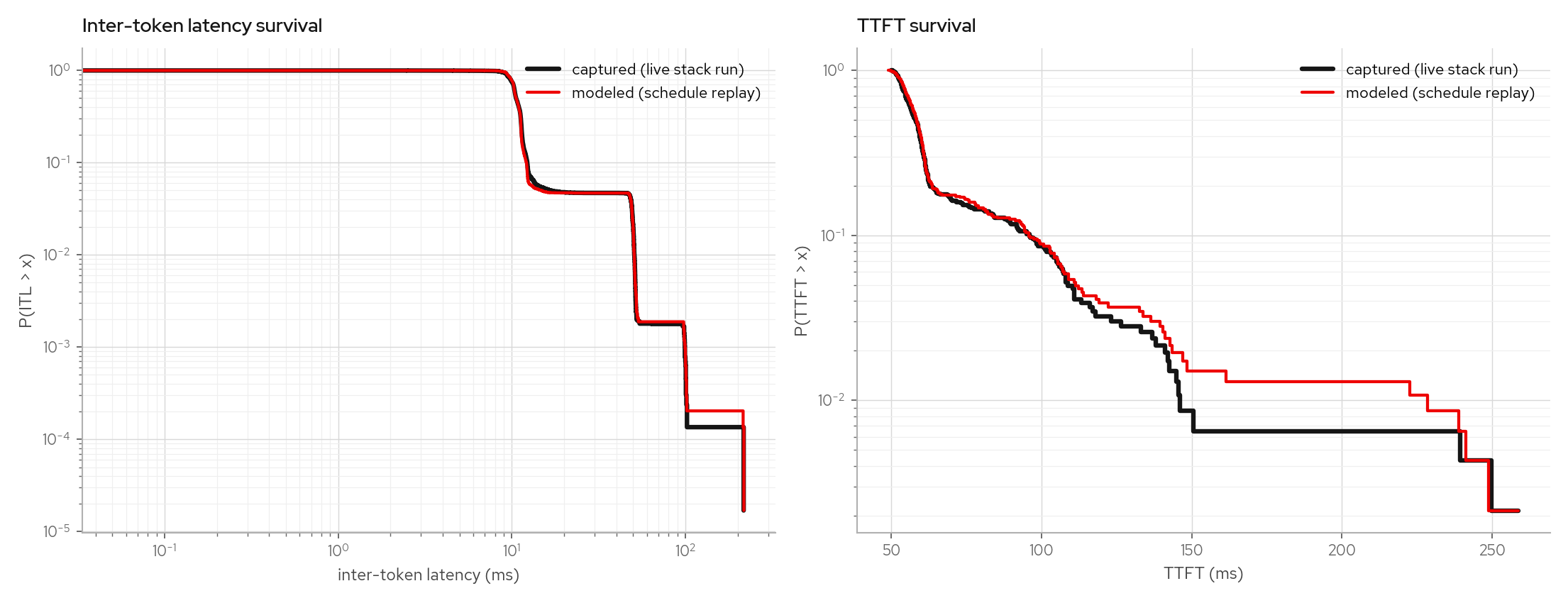
Per-concurrency-bucket rows shuffle under bursts (admission order inside a burst is not deterministic), which is why the gate compares pooled quantiles plus per-request decode totals.
Replayed prompts are unique-token synthetics: the captured workloads carry
cached_tokens: 0, and identical fill tokens would silently turn every replayed
request into a prefix-cache hit. Workloads with prefix reuse, such as multiturn and
agentic traces, also need prefix structure replayed; that is the next scenario.
To reproduce against any trace with arrival_ms:
# capture: any OpenAI-compatible target
uv run --with httpx deploy/trace-capture/loadgen.py --url http://127.0.0.1:8000 \
--model Qwen/Qwen3-8B --pattern poisson --rate 4 --duration 120 \
--prompt-tokens 512 --output-tokens 128 --out run.json --trace-out client.jsonl
# replay the schedule, fitting the model from a different capture
just replay tap-poisson.jsonl /tmp/fit.jsonl
# real-vs-replay survival curves (replay measurements via --dump-trace)
just compare "real=tap-poisson.jsonl" "replay=replay-measured.jsonl"