Prefix cache and agentic multiturn
The agentic scenario (loadgen.py --pattern multiturn) models sessions, not isolated
requests. Sessions arrive poisson at --rate; each session runs --turns closed-loop
turns whose context grows by the turn's prompt plus the model's response, on top of
one of --prefix-count shared --prefix-tokens prefixes. The validation run below
is about 100 sessions x 5 turns over two ~10k-token shared prefixes; 493 of 495
requests were prefix-cache hits.
Prefix caching is not a latency knob. The engine runs a block-pool prefix cache;
admission computes each request's cached-token count, the trace-fitted TTFT model
conditions on the uncached prompt size, and a prefill admission stalls concurrent
decodes by its uncached tokens. Replaying prefix-cache workloads requires the workload's
sharing structure. The tap fingerprints every prompt with chained per-block hashes
(block_hashes), and replay expands each distinct hash to one deterministic token
block. Replayed prompts therefore share prefixes at the same block boundaries as the
capture.
Two replay modes apply. Pure open-loop replay fires every turn at its recorded offset.
--replay-sessions restores the generator's semantics: turn N+1 fires when turn N
completes plus the recorded think gap, with sessions inferred from the hash chains.
Session pacing matches closed-loop client behavior. Cold turns take seconds, so later
turns are delayed by prior responses; open-loop replay would fire every turn on the
original warm schedule.
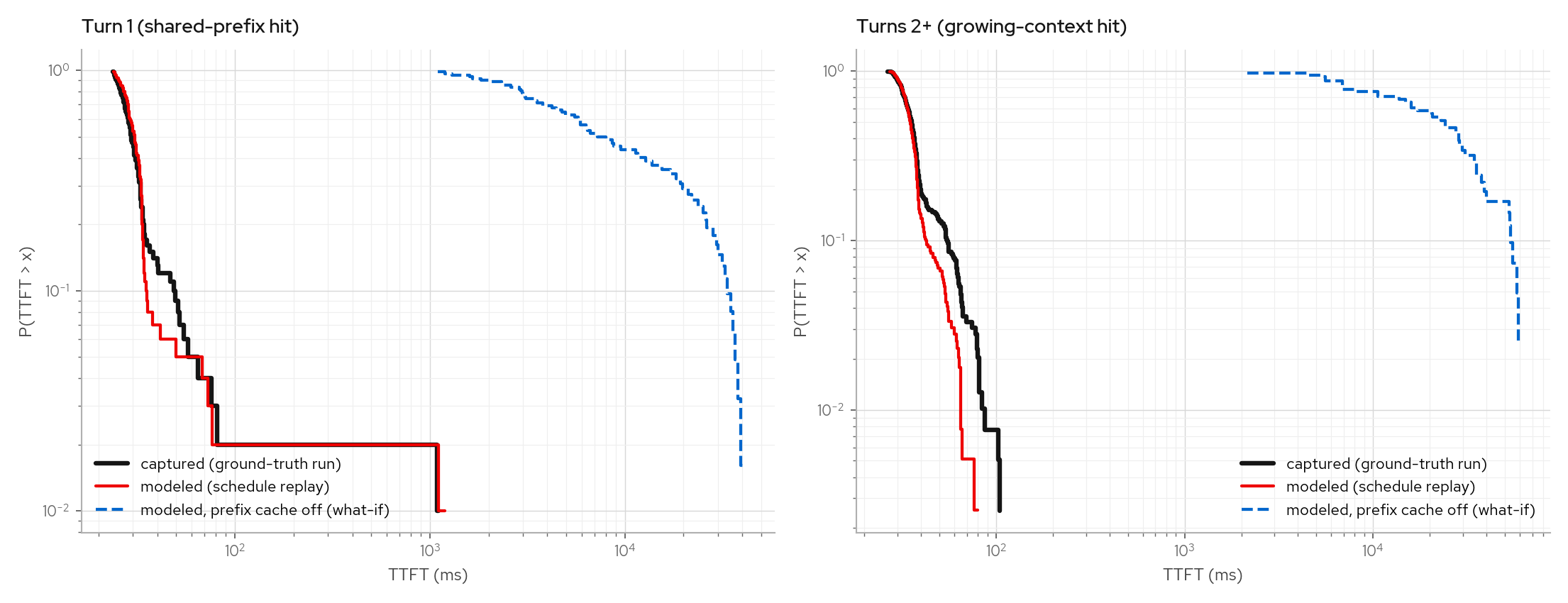
The figure shows captured vs modeled TTFT survival per turn cohort (turn-1 requests:
shared prefix hit only; turns 2+: growing context), plus the same schedule replayed
with --cold-prompts (prefix reuse disabled). Without the cache, every turn
re-prefills ~11k tokens and offered prefill load exceeds engine capacity. On turns 2+,
TTFT p50 changes from 36ms to ~24s and p99 from 87ms to ~59s, with closed-loop
sessions enabled.
# capture an agentic workload (10k-token shared prefixes at ~1.5 tokens/word)
uv run --with httpx deploy/trace-capture/loadgen.py --url http://127.0.0.1:8000 \
--model Qwen/Qwen3-8B --pattern multiturn --rate 1 --turns 5 \
--prefix-tokens 6500 --prompt-tokens 128 --output-tokens 128 --duration 120 \
--out run.json
# session-paced replay, then the cache-off replay
cargo run --release --bin vllm-vcr -- inspect calibrate-e2e tap-multiturn.jsonl \
--replay-arrivals --replay-sessions --latency-trace /tmp/fit.jsonl \
--sim-arg=--kv-cache-size --sim-arg=65536 --dump-trace replay-measured.jsonl
cargo run --release --bin vllm-vcr -- inspect calibrate-e2e tap-multiturn.jsonl \
--replay-arrivals --replay-sessions --cold-prompts ... --dump-trace nocache-measured.jsonl
# per-cohort figure
uv run scripts/plot_calibration.py --cache-effect real=tap-multiturn.jsonl \
--cache-effect replay=replay-measured.jsonl --cache-effect nocache=nocache-measured.jsonl \
--out-dir docs/images
The cold replay uses the chunk-cost model validated by the cold-multiturn counterfactual gate at this prompt scale. Workload traces with block-hash ids, lengths, and timestamps map onto this schema.